Benchmark of AMD Ryzen 9 7950X and NVIDIA RTX 4090
Francho Nerin Fonz
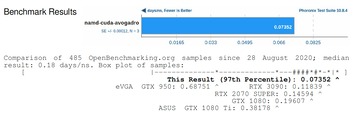
This is a report of benchmarks we ran on a desktop equipped with AMD Ryzen 9 7950X and NVIDIA RTX 4090.
Most of the benchmarks were run using the Phoronix Test Suite 10.8.4.
You can download the full report here.
This is a report of benchmarks we ran on a desktop equipped with AMD Ryzen 9 7950X and NVIDIA RTX 4090.
Most of the benchmarks were run using the Phoronix Test Suite 10.8.4.
You can download the full report here.
Benchmark of AMD Ryzen 9 7950 and NVIDIA RTX 4080
Makis Kounadis
Biomedical Research Foundation of the Academy of Athens, 4 Soranou Ephessiou, 11527 Athens, Greece
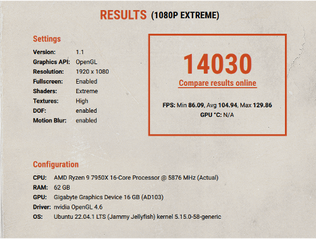
This is a report of benchmarks we ran on a desktop equipped with AMD Ryzen 9 7950x and NVIDIA RTX 4080.
You can download the full report here.
Biomedical Research Foundation of the Academy of Athens, 4 Soranou Ephessiou, 11527 Athens, Greece
This is a report of benchmarks we ran on a desktop equipped with AMD Ryzen 9 7950x and NVIDIA RTX 4080.
You can download the full report here.
Benchmark studies using GPU accelaration for large-scale molecular dynamics simulations of the Arp2/3 complex
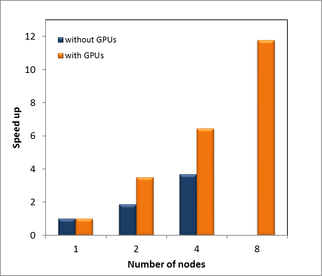
Speed-up over increasing number of GPU nodes for the Arp2/3 2VCA system.
Paraskevi Gkeka, George Patargias, Zoe Cournia
Biomedical Research Foundation of the Academy of Athens, 4 Soranou Ephessiou, 11527 Athens, Greece
The present report summarizes the benchmark study on GPU acceleration performed during the GPU CyTera Workshop that took place in the Cyprus Institute, Nicosia, 10-12 December 2012 for Cy-Tera project number lsprob10541. NAMD and GROMACS were tested for GPU acceleration on two systems: 1) A system with the Arp2/3-VCA complex in explicit water and 2) a system with the Arp2/3-2VCA-2actin complex in explicit water. The total size of the systems was approximately 350,000 and 600,000 atoms, respectively. According to the literature, runtimes of several hundreds of nanoseconds are required to identify putative VCA binding sites on Arp2/3 and to elucidate the structural details of Arp2/3 activation, which are the main goals of this project. Based on the size of the Arp2/3-VCA and Arp2/3-2VCA-2actin systems the specific project would greatly benefit by the use of a large cluster and GPU acceleration, as confirmed by the results presented herein.
You can download the full report here.
Biomedical Research Foundation of the Academy of Athens, 4 Soranou Ephessiou, 11527 Athens, Greece
The present report summarizes the benchmark study on GPU acceleration performed during the GPU CyTera Workshop that took place in the Cyprus Institute, Nicosia, 10-12 December 2012 for Cy-Tera project number lsprob10541. NAMD and GROMACS were tested for GPU acceleration on two systems: 1) A system with the Arp2/3-VCA complex in explicit water and 2) a system with the Arp2/3-2VCA-2actin complex in explicit water. The total size of the systems was approximately 350,000 and 600,000 atoms, respectively. According to the literature, runtimes of several hundreds of nanoseconds are required to identify putative VCA binding sites on Arp2/3 and to elucidate the structural details of Arp2/3 activation, which are the main goals of this project. Based on the size of the Arp2/3-VCA and Arp2/3-2VCA-2actin systems the specific project would greatly benefit by the use of a large cluster and GPU acceleration, as confirmed by the results presented herein.
You can download the full report here.
MD Benchmark studies using Gromacs on the Biblioteca Alexandrina Cluster
Ming Han, George Patargias, and Zoe Cournia
Biomedical Research Foundation of the Academy of Athens, 4 Soranou Ephessiou, 11527 Athens, Greece
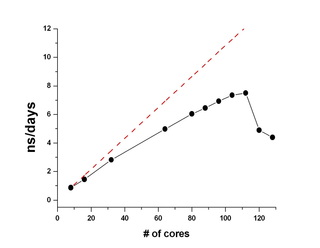
The present report summarizes the benchmark study of Gromacs scaling on a 200,000 atom-system using the Biblioteca Alexandrina cluster. Our results show that the MD calculation performance increases almost linearly with increasing core number 8 - 112. The performance is decreased when using more than 120 cores.
You can download the full report here.
Biomedical Research Foundation of the Academy of Athens, 4 Soranou Ephessiou, 11527 Athens, Greece
The present report summarizes the benchmark study of Gromacs scaling on a 200,000 atom-system using the Biblioteca Alexandrina cluster. Our results show that the MD calculation performance increases almost linearly with increasing core number 8 - 112. The performance is decreased when using more than 120 cores.
You can download the full report here.
Scaling studies up to 2048 cores on the CURIE and JUGENE HPC facilities for Molecular Dynamics simulations of the PI3Ka protein.
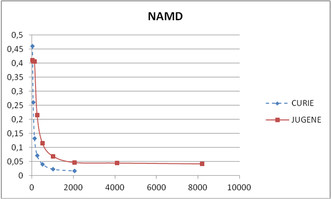
NAMD performance on the CURIE and JUGENE Supercomputers.
Paraskevi Gkeka and Zoe Cournia
Biomedical Research Foundation of the Academy of Athens, 4 Soranou Ephessiou, 11527 Athens, Greece
We performed Molecular Dynamics simulations of a 400,000 atom system using NAMD 2.8 and Gromacs 4.0 packages on CURIE and JUGENE. Our results show signficant scaling up to 2,048 cores on CURIE and JUGENE for both NAMD and GROMACS. However, NAMD and GROMACS performance was significantly smaller on JUGENE. On CURIE the nodes are connected via an Infiniband QDR network, while on JUGENE the nodes are connected via a 10-Gbit Ethernet network. As NAMD requires frequent and high throughput communication between nodes, it performed better on CURIE than on JUGENE. GROMACS performed compared to NAMD. However, also GROMACS performance was reduced on JUGENE though to a smaller extent, probably due to the use of Ethernet interconnects on JUGENE versus Infiniband on CURIE. More details can be found on the PRACE website: http://www.prace-ri.eu/PRACE-Preparatory-Access-cut-off.
The full report can be downloaded here.
Biomedical Research Foundation of the Academy of Athens, 4 Soranou Ephessiou, 11527 Athens, Greece
We performed Molecular Dynamics simulations of a 400,000 atom system using NAMD 2.8 and Gromacs 4.0 packages on CURIE and JUGENE. Our results show signficant scaling up to 2,048 cores on CURIE and JUGENE for both NAMD and GROMACS. However, NAMD and GROMACS performance was significantly smaller on JUGENE. On CURIE the nodes are connected via an Infiniband QDR network, while on JUGENE the nodes are connected via a 10-Gbit Ethernet network. As NAMD requires frequent and high throughput communication between nodes, it performed better on CURIE than on JUGENE. GROMACS performed compared to NAMD. However, also GROMACS performance was reduced on JUGENE though to a smaller extent, probably due to the use of Ethernet interconnects on JUGENE versus Infiniband on CURIE. More details can be found on the PRACE website: http://www.prace-ri.eu/PRACE-Preparatory-Access-cut-off.
The full report can be downloaded here.
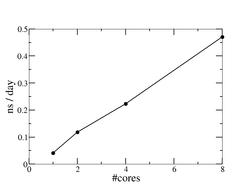 GROMACS performance on the GRNET node.
GROMACS performance on the GRNET node.
The lab participates in the UberCloud HPC Experiment Round 3 with the project: "TEAM 61 – Using Cloud Computing to Perform Molecular Dynamics Simulations of the Mutant PI3Kα Protein".
Download the full report here.
The Ubercloud HPC Experiment aims to explore the end-to-end process of accessing remote resources in computer centers and in HPC Clouds, and to study and overcome the potential roadblocks. Read more about it here.
Download the full report here.
The Ubercloud HPC Experiment aims to explore the end-to-end process of accessing remote resources in computer centers and in HPC Clouds, and to study and overcome the potential roadblocks. Read more about it here.
